MHK Data Lakes
What is a data lake?
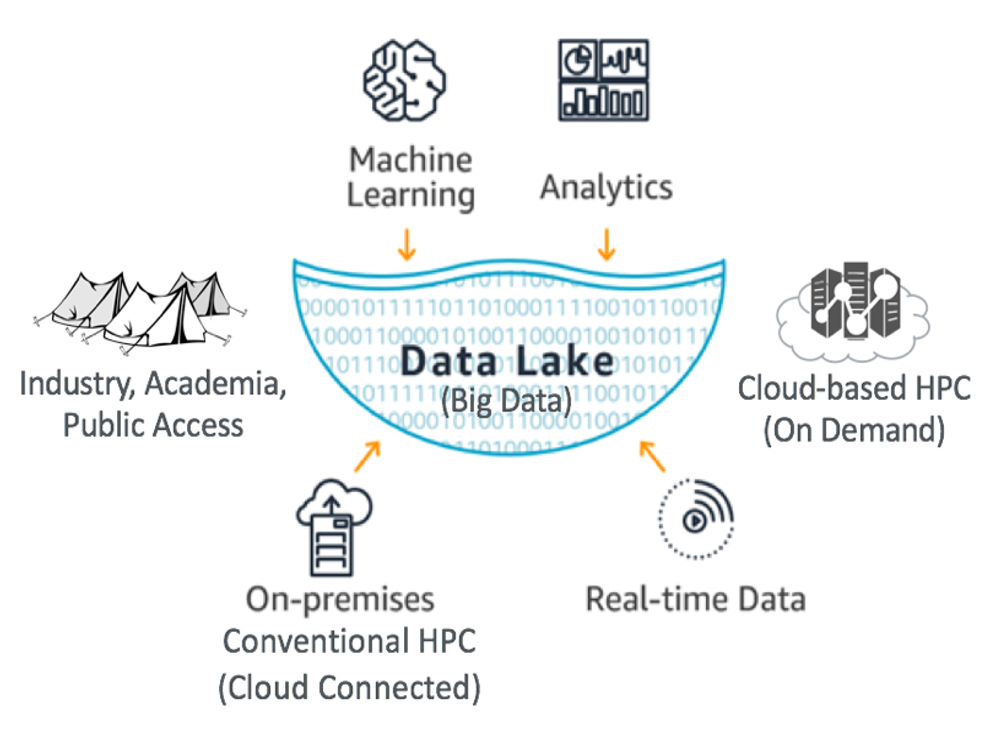
A data lake is a collection of curated and diverse datasets built to accelerate accessibility and collaboration. Data Lakes typically hold especially large or complex raw, processed, or supporting data files chosen by the contributing researchers. The lake enables sustained access to large data files, often through partnerships with a variety of cloud vendors.
Information flows into the Data Lake from a variety of sources: private industry, laboratories, analytic tools, use cases, research reports, and more. Next, the Data Lake's content is curated so that it is consistent and standardized. Once a Data Lake is curated it flows outward to the public and becomes universally accessible. Public access opens the door to potential collaboration between publication authors, researchers, universities, high schools, startup companies, and other innovators.
The availability and visibility of the Data Lakes remove barriers to innovation. The Data Lakes reduce duplication of effort by having a centralized location and reduces the cost of storage and analytics of large data sets. New insights and innovations flow outward from the lake, creating opportunities for even more rounds of research and development.
What belongs in the MHKDR data lake
The data lakes are an alternative storage model to the conventional data submission model, intended for especially large or complex datasets. There is no exact requirement to denote what is considered especially large or complex, but generally, if your dataset is on the order of terabytes in size (or larger), if it has multiple nested layers (e.g., hierarchical data format), or if it is cloud-optimized, it could be a good fit for the data lake. We recommend storing data files and complex metadata files in the data lake, and saving scientific reports, supporting media, and links to online documents for the submission form that will accompany your data lake submission.
Universal Accessibility
Our open architecture is designed for universal access and dissemination of big data. Data Lakes can be accessed via our cloud partners. There are a few ways to utilize Data Lakes. Jupyter notebooks are a common option for utilizing Data Lakes datasets. However, there are many options for processing Data Lakes.
- Jupyter notebooks (example)
- Google Earth Engine
- Direct access to Data Lakes (Requires a cloud account.)
- Data Lake Viewer (Currently only AWS)
- Native cloud command line tools (AWS, Google, Azure)
- Mounting the data as a local read-only drive in a cloud-built computer cluster. Requires same availability zone.
How to submit data to the MHKDR data lakes?
If you are interested in submitting your data to the MHKDR data lakes, check out our data lake submission process page.
Data Lakes Datasets
0
Datasets
0
Accessed
(this year)
0
of Data
| Submission | Availability | Size | Status | Data from |
|---|---|---|---|---|